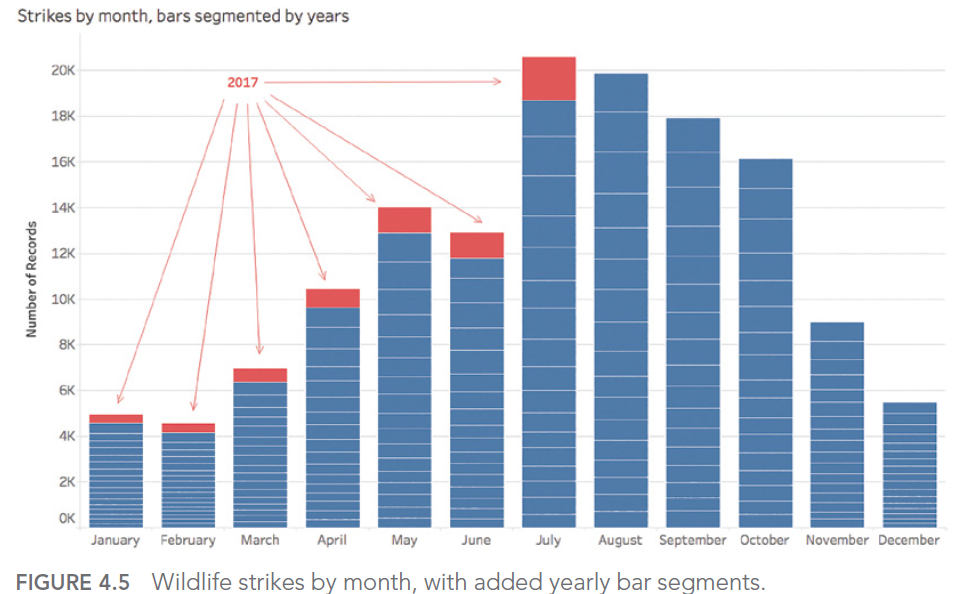
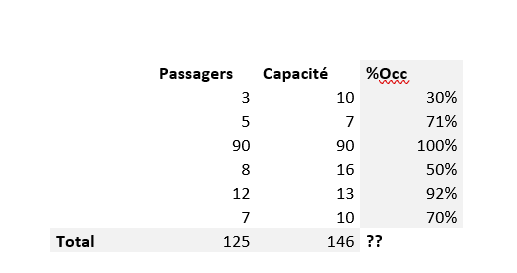
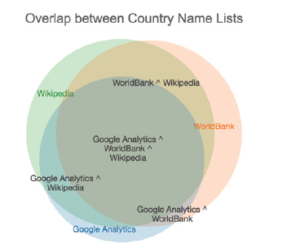
TAGADA Ltd. testifies: BLC, a key partner in data management and AI innovation
Local expertise
From Data to Intelligence
Preparing the future of data management
At Business Lab Consulting, we’re proud to share feedback from our customers. Today, we present a testimonial from 𝐓𝐚𝐠𝐚𝐝𝐚 𝐋𝐭𝐝.
Christophe LOUVET, ex-head of the Data division, gives us his impressions of our collaboration.
Meeting the challenges of data and AI
At Business Lab Consulting (BLC), we’re proud to share our customers’ feedback. Today, we present a testimonial from TAGADA Ltd., a company that called on our services to optimize its data management and prepare its future in the age of artificial intelligence.
TAGADA Ltd. is facing major challenges in the field of data, particularly in terms of integrating AI into their processes. Christophe LOUVET, ex-TAGADA Ltd’s Data Manager, gives us his impressions of our collaboration.
“With the rapid evolution of the data field and the increasing integration of AI into processes, we are often faced with the need to conduct searches across our various databases.”
This situation requires careful data preparation to ensure smooth and efficient searches. The company recognizes the crucial role AI can play in facilitating these processes, and is keen to integrate it further into its data management.
The impact of BLC on TAGADA Ltd.
Our collaboration has had a significant impact on TAGADA Ltd’s services.
“The expertise of the BLC teams, as well as their skills in important areas of data, enable us to meet our internal needs as well as those of our customers.”
Thanks to our expertise, TAGADA Ltd. was able to implement solutions tailored to their data, while ensuring reliable processes.
Why choose BLC's services?
TAGADA Ltd.’s decision to use our services is based on one key advantage:
- The geographical proximity of our teams in Mauritius offers several advantages:
- Smoother processes
- Improved responsiveness
- Easier exchanges
- The possibility of face-to-face meetings, notably for monthly meetings
BENEFITS
TAGADA Ltd. was particularly impressed by two aspects of our service:
- Our responsiveness
- Our constructive proposals in response to their needs
According to the Data Manager, we have the « ability to present different options », which enabled them to make the best choices for their company and their customers.
TAGADA Ltd. highlights several of BLC’s key strengths:
- Our localization
- Responsiveness
- In-depth knowledge of data management in different sectors
- Our expertise
- Our proactivity in anticipating potential problems
- « Follow-up and support are good. You are responsive to our requests and provide good advice concerning developments and the strategy to adopt. »

Scope for improvement
TAGADA Ltd. suggests that we focus more of our efforts on developing AI-based solutions for data management, highlighting the growing importance of this technology in their field. With several ongoing projects on the subject, we’re certainly in line with their recommendations.
A comprehensive and rewarding service
“BLC provides us with invaluable technical expertise, responsiveness and proximity, while offering solutions tailored to our data management needs and anticipating future AI-related challenges.”
A solid recommendation
TAGADA Ltd. rates its satisfaction at 8/10, a score that reflects the high quality of our services and the work of our expert team.