RETAIL: Data Science & Insights // S3E3
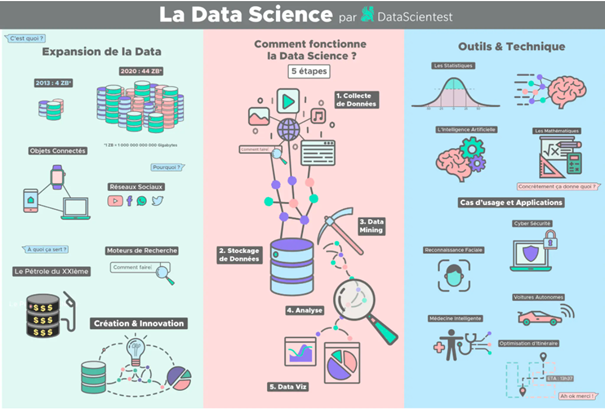
La Data Science est la science des données. C’est un ensemble de techniques et de méthodes qui permettent à une organisation d’analyser ses données brutes pour en extraire des informations précieuses permettant de répondre à des besoins spécifiques ou de résoudre des problèmes analytiques complexes.
La Data Science permet de découvrir des informations pertinentes au sein des ensembles de données
En plongeant dans ces informations à un niveau fin, l’utilisateur peut découvrir et comprendre des tendances et des comportements complexes. Il s’agit de faire remonter à la surface des informations pouvant aider les entreprises à prendre des décisions plus intelligentes.
Cette « fouille de données » peut se faire grâce à l’apprentissage automatique (Machine Learning). Ce dernier fait référence au développement, à l’analyse et à l’implémentation de méthodes et algorithmes qui permettent à une machine (au sens large) d’évoluer grâce à un processus d’apprentissage, et ainsi de remplir des tâches qu’il est difficile ou impossible de remplir par des moyens algorithmiques plus classiques.
La Data Science permet de créer un Data Product
Un data product est un outil qui repose sur des données et les traite pour générer des résultats à l’aide d’un algorithme. L’exemple classique d’un data product est un moteur de recommandation.

Moteur de recommandation
Il a été rapporté que plus de 35% de toutes les ventes d’Amazon sont générées par leur moteur de recommandation. Le principe est assez basique : en se basant sur l’historique des achats d’un utilisateur, les articles qu’il a déjà dans son panier, les articles qu’il a notés ou aimés dans le passé et ce que les autres clients ont vu ou acheté récemment, des recommandations sur d’autres produits sont automatiquement générées.
Optimiser votre gestion de stock
Un autre exemple de cas d’usage de la data science est l’optimisation de l’inventaire, les cycles de vie des produits qui s’accélèrent de plus en plus et les opérations qui deviennent de plus en plus complexes obligent les détaillants à utiliser la Data Science pour comprendre les chaînes d’approvisionnement et proposer une distribution optimale des produits.
Optimiser ses stocks est une opération qui touche de nombreux aspects de la chaîne d’approvisionnement et nécessite souvent une coordination étroite entre les fabricants et les distributeurs. Les détaillants cherchent de plus en plus à améliorer la disponibilité des produits tout en augmentant la rentabilité des magasins afin d’acquérir un avantage concurrentiel et de générer de meilleures performances commerciales.
Ceci est possible grâce à des algorithmes d’expédition qui déterminent quels sont les produits à stocker en prenant en compte des données externes telles que les conditions macroéconomiques, les données climatiques et les données sociales. Serveurs, machines d’usine, appareils appartenant au client et infrastructures de réseau énergétique sont tous des exemples de sources de données précieuses.

Ces utilisations innovantes de la Data Science améliorent réellement l’expérience client et ont le potentiel de dynamiser les ventes des détaillants. Les avantages sont multiples : une meilleure gestion des risques, une amélioration des performances et la possibilité de découvrir des informations qui auraient pu être cachées.

")